
- AWS Database ServiceS,
- Amazon RDS (Relational Database Service),
- Relational vs NonRelational
- RDS Multi-AZ Deployments,
- RDS Read Replicas,
- Amazon Aurora,
- Amazon DynamoDB,
- DynamoDB Streams
- Amazon RedShift
In this module, we will discuss AWS database solutions, such as:
– Exploring the variety of cloud-based database services.
– Identifying the contrasts between managed and un-managed database systems.
– Understanding the differences between SQL and NoSQL database types.
– Evaluating how various database solutions differ in terms of availability.
This module aims to equip you with knowledge about the database tools available to support your solution. Additionally, you’ll explore the features of different services to grasp how your choices can influence factors like availability.
Amazon Relational Database Service.
Welcome to an overview of the fundamental database services offered by Amazon Web Services (AWS). This module will introduce you to the Amazon Relational Database Service (Amazon RDS).
In this section, you’ll examine the contrasts between managed and un-managed services, particularly in relation to Amazon RDS. AWS solutions typically fall into two categories: managed or un-managed.
Amazon RDS is a managed service that simplifies the process of setting up and running relational databases in the cloud.
To overcome the difficulties of maintaining an un-managed, standalone relational database, AWS offers a solution that automates the setup, operation, and scaling of a relational database without requiring continuous oversight. Amazon RDS delivers scalable and cost-effective capacity, while handling administrative tasks like backups and patching.
With Amazon RDS, you can concentrate on improving your application’s performance, security, availability, and compatibility. Your focus remains on your data and optimizing your app, while RDS takes care of the rest.
Un-managed services typically require users to provision resources and manage them as needed. For example, if you launch a web server on an Amazon Elastic Compute Cloud (Amazon EC2) instance, you are responsible for managing traffic spikes, errors, and failures. Since EC2 is an unmanaged service, you would need to implement solutions like AWS Auto Scaling to manage increased demand or handle malfunctioning instances. The advantage of an unmanaged service is that you have precise control over how your system reacts to changes in traffic, errors, and downtime.
Managed services, on the other hand, require less user involvement for setup and configuration. For example, creating a bucket in Amazon Simple Storage Service (Amazon S3) involves setting permissions, but most other functions—like scaling, fault tolerance, and availability—are handled automatically by AWS. When hosting a static website in an Amazon S3 bucket, there’s no need for a web server, as the service takes care of key operational concerns. Next, you’ll examine the challenges of managing a standalone, un-managed relational database, followed by an explanation of how Amazon RDS overcomes these hurdles.

So, what exactly is a managed service?
When managing an on-premises database, a database administrator (DBA) is responsible for all tasks, including optimizing performance, configuring hardware, patching, and maintaining the network, power, and climate control systems. If you move your database to an Amazon EC2 instance, you no longer need to manage physical hardware or data center operations. However, you’re still responsible for tasks like OS updates, software patching, and backups.
Switching to Amazon RDS or Amazon Aurora reduces your administrative load. Cloud-based solutions enable automatic scaling, high availability, and managed backups and updates, allowing you to focus on optimizing your application.
In a managed service like Amazon RDS, your responsibilities include:
– Application optimization
While AWS handles:
– Installing and patching the operating system
– Database software installation and updates
– Automatic backups
– Ensuring high availability
– Scaling
– Power management and server maintenance
By using Amazon RDS, your operational burden is reduced as AWS manages the infrastructure, patches, and backups, freeing you to concentrate on improving your application. This results in lower costs and less maintenance for your relational database.
Now, let’s take a brief look at the service and some potential use cases.
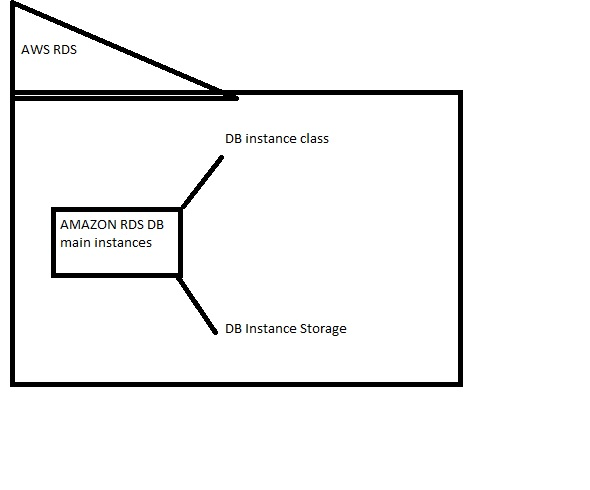
Amazon RDS DB Instances
The core component of Amazon RDS is the database instance, which is an isolated environment where multiple databases can be created. You can interact with these databases using the same tools and applications as you would with a standalone database. The performance and cost of a database instance depend on its class and storage type. When creating a database instance, you first choose the database engine to use. Currently, Amazon RDS supports six engines: MySQL, Amazon Aurora, Microsoft SQL Server, PostgreSQL, MariaDB, and Oracle.
Amazon RDS in a Virtual Private Cloud (VPC)
You can run a database instance within an Amazon Virtual Private Cloud (Amazon VPC). Using a VPC allows you to configure your virtual network environment, including selecting IP address ranges, creating subnets, and managing routing and access control lists (ACLs). Whether or not your instance runs in a VPC, the basic functionality of Amazon RDS remains the same. Typically, the database instance is housed in a private subnet and is only accessible to designated application instances. Subnets within a VPC are tied to specific Availability Zones, so when choosing a subnet, you are also selecting the physical location for your database instance.
One of the key advantages of Amazon RDS is the option to set up your database instance for high availability using a Multi-AZ deployment. When this configuration is enabled, Amazon RDS automatically creates a replica of the database instance in a different Availability Zone within the same VPC. Once the replica is initialized, transactions are synchronously mirrored to the standby instance. Utilizing a Multi-AZ deployment boosts availability during routine maintenance and provides resilience against database instance failures or interruptions within a specific Availability Zone.
In the event that the primary database instance experiences a failure in a Multi-AZ setup, Amazon RDS automatically promotes the standby instance to become the new primary. The use of synchronous replication helps to significantly reduce the risk of data loss. Since your applications connect to the database using the Amazon RDS DNS endpoint, no changes are required in your application code for the fail-over to occur seamlessly.
Amazon RDS in a virtual private cloud (VPC)
Unmanaged Services: These solutions require users to provision and manage all aspects of the service themselves. For example, if you deploy a web server on an Amazon EC2 instance, you must handle scaling, load management, and system failures manually. EC2 does not provide automatic scaling or instance recovery unless you configure a service like Auto Scaling. The advantage of this approach is greater control and flexibility in responding to various operational challenges, but it also demands more responsibility and technical expertise from the user.
Managed Services: Managed services take care of much of the operational overhead, reducing the amount of configuration and management needed. For instance, when you create an Amazon S3 bucket, you only need to configure basic settings like permissions, and the platform automatically handles scaling, fault tolerance, and high availability. As a result, managed services simplify operations, allowing you to focus more on application logic and less on infrastructure management.
Next, let’s look at the complexities involved in running a self-managed relational database. Following this, we’ll explore how Amazon RDS mitigates these challenges. Running your own relational database system requires handling several tasks such as server maintenance, patching, backups, scaling, security, and OS updates. Each of these tasks demands expertise and time, detracting from your ability to focus on application development. Amazon RDS, a managed database service, reduces the administrative burden by automating tasks such as backups, patching, and scaling, so you can prioritize application performance and data optimization.
AWS offers Amazon RDS to help address these challenges by providing a fully managed database service. Amazon RDS automates many tedious administrative tasks and offers cost-efficient, scalable solutions. This means that instead of focusing on database management, you can shift your attention to optimizing your data and application.
Managed services in AWS reduce the complexity of database administration. When managing a database on-premises, the administrator is responsible for everything—from hardware setup and optimization to power, HVAC, and networking. If you switch to a cloud-based database running on an EC2 instance, you still need to handle tasks such as OS patching and software maintenance. But if you use Amazon RDS or Amazon Aurora, many of these responsibilities are offloaded to AWS, including automatic scaling, high availability, backups, and patching, letting you focus on application-level optimization.
With RDS, AWS handles most of the operational aspects, such as power management, server maintenance, and scaling, thus reducing the workload on your team and lowering the costs associated with database administration. The core unit of Amazon RDS is the database instance. This isolated environment can support multiple user-created databases and can be accessed using standard database tools. The performance and cost of each instance depend on its class and storage type, allowing you to tailor the service to your specific needs.
You can deploy your database instance within an Amazon Virtual Private Cloud (VPC), which gives you more control over your networking environment. VPC lets you choose your own IP address range, subnets, and access control lists. Whether your database instance is within a VPC or not, the basic functionality remains the same. However, most RDS instances are placed in private subnets and are only accessible to specified application instances. When you select a subnet, you are also choosing the Availability Zone, which corresponds to the physical location of your database.
The cost and performance of database instances vary depending on the instance class and storage type, allowing you to adjust based on your database’s requirements. When setting up a database instance, you must first choose the database engine you want to run. RDS supports six types of databases: MySQL, Amazon Aurora, PostgreSQL, Microsoft SQL Server, Oracle, and MariaDB. One of the standout features of Amazon RDS is its Multi-AZ deployment option, which significantly improves availability.
When using Multi-AZ, RDS automatically creates a standby replica in another Availability Zone within the same VPC. Changes made to the primary database are replicated in real time to this standby instance. If the primary instance fails, the standby instance automatically takes over, ensuring minimal downtime and preventing data loss. Moreover, because applications connect to RDS through a Domain Name System (DNS) endpoint, there’s no need to modify the application code during a failover.
Amazon RDS also offers the ability to create read replicas for certain databases, such as MySQL, MariaDB, PostgreSQL, and Amazon Aurora. These replicas asynchronously replicate data from the primary database, which allows you to route read-heavy traffic to these replicas, reducing the load on the primary instance. Read replicas can also be promoted to primary databases, though this process must be initiated manually. You can even create read replicas in different regions, which can be beneficial for disaster recovery and reducing latency by serving users from a geographically closer database replica.
Amazon RDS is ideal for applications with high throughput, scalability, and availability requirements, such as web and mobile applications. Because it lacks licensing restrictions, it’s especially well-suited for businesses with fluctuating traffic patterns, such as e-commerce sites. RDS provides a secure, cost-effective solution for online retail platforms, enabling businesses to handle spikes in traffic without worrying about infrastructure limitations. Mobile and online games that demand high availability and throughput also benefit from RDS, as the service takes care of provisioning, scaling, and monitoring the database infrastructure.
Amazon RDS is a suitable choice for applications that require:
- Complex transactions or queries
- Medium to high query rates (up to 30,000 IOPS)
- Single worker node or shard
- High durability and availability
However, RDS might not be the best fit for applications requiring:
- Extremely high read/write rates (e.g., 150,000 writes per second)
- Sharding due to large data volumes or throughput demands
- Simple GET/PUT requests, which are better suited for NoSQL databases
- Customization of the relational database management system (RDBMS)
For applications with such requirements, a NoSQL solution like DynamoDB may be a better fit. Alternatively, running your database engine on EC2 instances instead of RDS will give you greater customization options.
In conclusion, Amazon RDS offers a fully managed database service that minimizes the operational burden and allows you to focus on optimizing your application and data. By automating tasks such as backups, patching, and scaling, RDS ensures high availability and cost-efficient performance. The Multi-AZ deployment and read replicas features further enhance its reliability, making it a strong choice for a wide range of web, mobile, and enterprise applications. However, for applications with more extreme performance needs or those requiring heavy customization, EC2 or a NoSQL solution may be more appropriate.
To further expand on the key concepts related to cloud-based database solutions, it is essential to explore the broader context of how database services are transforming the way organizations manage their data. Cloud database solutions offer a level of flexibility, scalability, and cost-effectiveness that traditional on-premise database systems struggle to match. By moving to cloud-based databases, organizations can reduce their operational burden and focus on driving innovation, developing products, and enhancing customer experiences. Cloud solutions free database administrators from the constraints of physical infrastructure and provide tools for better data management, security, and high availability.
Managed vs. Unmanaged Databases: A Deeper Dive
Understanding the differences between managed and unmanaged databases is crucial for selecting the right cloud solution. With unmanaged services, users have greater control over how they configure and manage their databases. While this provides the flexibility to optimize every component according to specific needs, it also increases the complexity and administrative overhead. For example, using Amazon EC2 to host a database allows for fine-grained control over the instance type, storage, and performance, but the user must manually handle tasks like software updates, backups, and disaster recovery.
In contrast, managed services such as Amazon RDS and Amazon Aurora reduce this complexity by automating many of the tedious administrative tasks, such as patching, backup management, and scaling. This automation is especially valuable for businesses that want to focus on their core applications rather than maintaining the infrastructure. Managed services are ideal for those who require a reliable and scalable database without the need for constant oversight and manual interventions.
SQL vs. NoSQL: Choosing the Right Database Model
When evaluating cloud database services, another critical consideration is whether to use SQL or NoSQL databases. SQL databases, such as MySQL, PostgreSQL, and Oracle, are relational databases that use structured query language (SQL) to manage and query data. They are highly suited for applications that require complex queries, transactions, and adherence to data integrity rules. Amazon RDS supports several relational database engines, providing users with a variety of choices depending on their specific use case.
On the other hand, NoSQL databases like Amazon DynamoDB offer a flexible data model that is often better suited for applications requiring high-speed read/write operations and handling unstructured data. NoSQL databases do not rely on predefined schemas, making them an excellent choice for applications with dynamic or unpredictable data patterns. For instance, social media platforms and real-time analytics systems often use NoSQL databases due to their ability to scale horizontally and handle vast amounts of data with minimal latency.
Availability and Disaster Recovery
Cloud database solutions also excel in ensuring high availability and disaster recovery. Amazon RDS, for example, provides automatic Multi-AZ deployments, which replicate data across multiple availability zones to ensure that if one instance fails, another can take over without data loss or significant downtime. This level of built-in redundancy is critical for businesses that cannot afford any disruptions in their operations. In addition, Amazon RDS offers read replicas, allowing applications to route read-heavy workloads to replica instances, thus improving performance and scaling beyond the capacity of a single database instance.
For disaster recovery, the option to place read replicas in different regions further enhances the resilience of cloud databases. This setup helps organizations meet disaster recovery objectives by minimizing downtime and maintaining service continuity even in the event of a regional failure. Additionally, read replicas located in geographically dispersed regions can reduce latency for users in different parts of the world, enhancing the overall user experience.
Use Cases and Practical Applications
The use cases for managed cloud database services like Amazon RDS are vast and cover a wide range of industries. E-commerce platforms, for instance, benefit from RDS’s ability to handle complex transactions, manage large amounts of data, and provide high availability, making it a perfect fit for online retail applications. Similarly, mobile applications that require rapid scaling to accommodate unpredictable user traffic can leverage Amazon RDS for its automatic scaling features, allowing the backend infrastructure to grow as the application demand increases. Furthermore, online gaming platforms, which often require high throughput and low latency, can rely on the cloud’s managed services to deliver a seamless user experience.
In conclusion, cloud-based database solutions are revolutionizing data management by offering scalable, flexible, and automated options that reduce the administrative burden on organizations. By carefully considering the differences between managed and unmanaged services, SQL and NoSQL databases, and leveraging the built-in availability and disaster recovery features of services like Amazon RDS, businesses can significantly enhance their database infrastructure. The choice of database solution should align with the specific needs of the application, ensuring optimal performance, security, and cost-effectiveness.
Amazon RDS: Billing Based on Usage and Database Features
When calculating the cost of using Amazon RDS, it’s important to factor in the hours the service is actively running. Charges accrue for the time the database instance is operational, starting from the moment it’s launched until it’s shut down or terminated.
Additionally, the characteristics of the database itself impact the cost. Factors such as the type of database engine, instance size, and memory specifications all influence the pricing. Different combinations of these features will lead to variations in your final costs.
Amazon RDS: Instance Types and Multiple Instances
Another consideration is the type of instance you choose. On-Demand Instances allow you to pay for compute power by the hour, offering flexibility without any long-term commitments. Reserved Instances, on the other hand, offer the option of making a one-time upfront payment in exchange for a discounted rate for a 1-year or 3-year commitment, which can lead to cost savings over time.
Furthermore, you should think about the number of instances required. Amazon RDS allows you to run multiple database instances simultaneously, which can help manage high traffic and peak workloads more effectively.
Amazon RDS: Storage Costs
Storage is another important factor. For active databases, Amazon RDS includes backup storage of up to 100% of the provisioned database size at no extra cost. However, once the instance is terminated, backup storage is charged based on the amount used, calculated on a per-gigabyte, per-month basis.
In addition to the provisioned storage, any extra backup storage consumed will also incur charges, which are similarly billed based on the amount of data stored per gigabyte each month. It’s important to monitor both your provisioned and backup storage usage to manage costs effectively.
Pricing
You should also take into account the number of input and output operations being performed on the database.
When selecting a deployment option, you can either deploy your database instance in a single Availability Zone (similar to an independent data center) or across multiple Availability Zones (comparable to a backup data center to boost availability and reliability). The storage and I/O costs will differ depending on the number of Availability Zones you use.
Additionally, consider data transfer costs. Incoming data transfer is free, while outgoing data transfer fees are tiered based on usage.
To manage expenses more effectively for Amazon RDS database instances, you can opt for Reserved Instances. By making an upfront payment for each Reserved Instance, you can benefit from a substantial discount on the hourly usage rate for that instance.
Relational Database vs Non Relational Database
Relational Databases
A relational database, also known as a Relational Database Management System (RDBMS) or SQL database, organizes data in rows and columns, also known as records within tables. This concept was first introduced in 1970 by E.F. Codd, an IBM researcher, in his work titled A Relational Model of Data for Large Shared Data Banks. Over time, well-known relational databases such as Microsoft SQL Server, Oracle Database, MySQL, and IBM DB2 gained prominence. Many of these platforms also offer free versions, such as SQL Server Express, PostgreSQL, SQLite, MySQL, and MariaDB.
Relational databases use the concept of “keys” to connect data across multiple tables. A key is a distinct identifier assigned to each row in a table. When this identifier, called a “primary key,” is referenced in another table to indicate a relationship, it is termed a “foreign key.” The relationship between primary and foreign keys is the foundation of how data is related across different tables in a relational database.
For example, in an Employee table, each employee may have a unique EmployeeId as a primary key. A separate Sales table could have multiple sales entries tied to the same employee through their EmployeeId, which would serve as the foreign key in the Sales table.
Benefits of Relational Databases
One primary advantage of RDBMSs is “referential integrity,” ensuring data remains accurate and consistent by using keys. Referential integrity is upheld through constraints, which set rules to prevent the deletion of related data before its primary record is deleted. If you try to remove a primary record without deleting related entries in other tables, the system will prevent the action. This prevents “orphaned records,” where linked records remain without their original reference.
Rules for Referential Integrity
Referential integrity ensures that:
- Every foreign key must have a matching primary key (no orphaned records).
- Deleting a record in a primary table also deletes any related records (usually done through cascade delete).
- When a primary key is updated, corresponding foreign keys in other tables are also updated (cascade update).
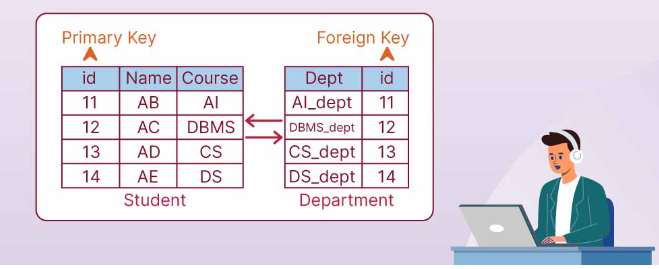
Ref: https://www.shiksha.com/online-courses/articles/difference-between-primary-key-and-foreign-key/
Querying Data in a Relational Database
SQL (Structured Query Language) is the standard language for interacting with a relational database. SQL allows users to create, retrieve, update, and delete records, often relying on the relationships between tables through primary and foreign keys. This makes relational databases ideal for applications needing complex reports, data mining, or strong transactional support.
For example, to retrieve all sales records made by an employee with EmployeeId = 1, an SQL query might look like this:
SELECT * FROM Employees
JOIN Sales ON Employees.EmployeeId = Sales.EmployeeId
WHERE EmployeeId = 1;SQL queries can also involve multiple table joins, allowing for detailed data retrieval across different tables:
SELECT * FROM Employees
JOIN Sales ON Employees.EmployeeId = Sales.EmployeeId
JOIN Customers ON Customers.CustomerId = Sales.CustomerId
WHERE EmployeeId = 1;To speed up data retrieval, relational databases use “indexes,” which are specialized data structures that optimize queries. For instance, indexing the EmployeeId or CustomerId fields would make these queries more efficient.
Non-relational Databases
In contrast, non-relational databases (NoSQL) store data in ways other than the structured tables used in relational systems. They don’t require tables, rows, or keys but instead use flexible storage models suited for handling specific types of data. Popular NoSQL databases include MongoDB, Apache Cassandra, Redis, Couchbase, and Apache HBase.
Types of Non-relational Databases
- Document Stores: Store data in a document format (often JSON) with fields and values. This structure allows flexible querying and filtering without requiring all documents to have the same format.
- Column-oriented Databases: Data is stored in columns, optimizing sparse data and enabling efficient data retrieval.
- Key-value Stores: The simplest form of NoSQL databases, storing data as key-value pairs.
- Graph Databases: Best suited for storing relationships between data points, such as interconnected records in a supply chain or a social network.
Relational vs. Non-relational Databases: A Comparison
- Relational databases excel at handling structured data, ensuring strong data integrity and offering advanced indexing for faster queries. They are highly suitable for applications that rely on complex transactions and require strict consistency, such as financial systems.
- Non-relational databases provide more flexibility, especially for handling unstructured or semi-structured data. They are ideal for rapidly changing requirements and applications that need scalability and high availability, such as social media platforms or big data analytics.
In the end, choosing between a relational and non-relational database depends on the specific needs of your application and the type of data you are working with.
Differences between Relational Database and non-relational Database
| Features | Relational Databases | Non-relational Databases (NoSQL) |
|---|---|---|
| Data Structure | Works with structured data in tables (rows and columns). | Handles large volumes of data with minimal structure, often supporting unstructured data. |
| Data Integrity | Enforces data integrity through relationships and constraints. | Offers flexibility without strict constraints, but may lack the strong data integrity of relational models. |
| Indexing | Supports extensive indexing capabilities for faster query response times. | Indexing options vary depending on the NoSQL database type, but generally provide good performance for specific data models. |
| Transaction Security | Ensures strong security for data transactions. | May not be as robust in transactional security but offers flexibility in development. |
| Querying Language | Uses Structured Query Language (SQL) for complex data queries and analysis. | Does not use SQL; relies on other querying techniques, often involving application-specific languages (e.g., MongoDB Query Language). |
| Business Rule Enforcement | Supports business rules at the data layer, enhancing integrity. | Lacks built-in enforcement of business rules but is flexible for rapid development. |
| Orientation | Data is organized in tables and rows. | Data can be stored in various forms such as documents, key-value pairs, or graph structures. |
| SQL Examples | MySQL, Oracle, SQLite, PostgreSQL, MS-SQL | MongoDB, BigTable, Redis, RavenDB, Cassandra, HBase, Neo4j, CouchDB |
| Best Use Cases | Ideal for heavy transactional systems and complex queries. | Best suited for applications requiring scalability, flexibility, and the ability to handle diverse, rapidly evolving data models. |
| Scalability and Flexibility | Provides scalability but is more rigid compared to NoSQL databases. | Highly scalable and flexible to adapt to evolving business needs. |
| Schema | Schema-based, requiring predefined structure. | Supports schema-free or schema-on-read models, allowing flexibility in data representation. |
| Big Data Handling | Not optimized for handling vast amounts of unstructured data. | Specializes in handling Big Data, especially unstructured and semi-structured data. |
| Development Speed | Requires more planning and setup for structured environments. | Suitable for rapid development with minimal schema restrictions. |
| Modeling Flexibility | Less flexible, as the structure must be predefined and maintained. | Provides flexible models to store and merge data without requiring schema modifications. |
| Recommended Use | Best for applications requiring complex transactions, high integrity, and structured data management. | Ideal for dynamic applications requiring scalability, flexibility, and rapid prototyping. |

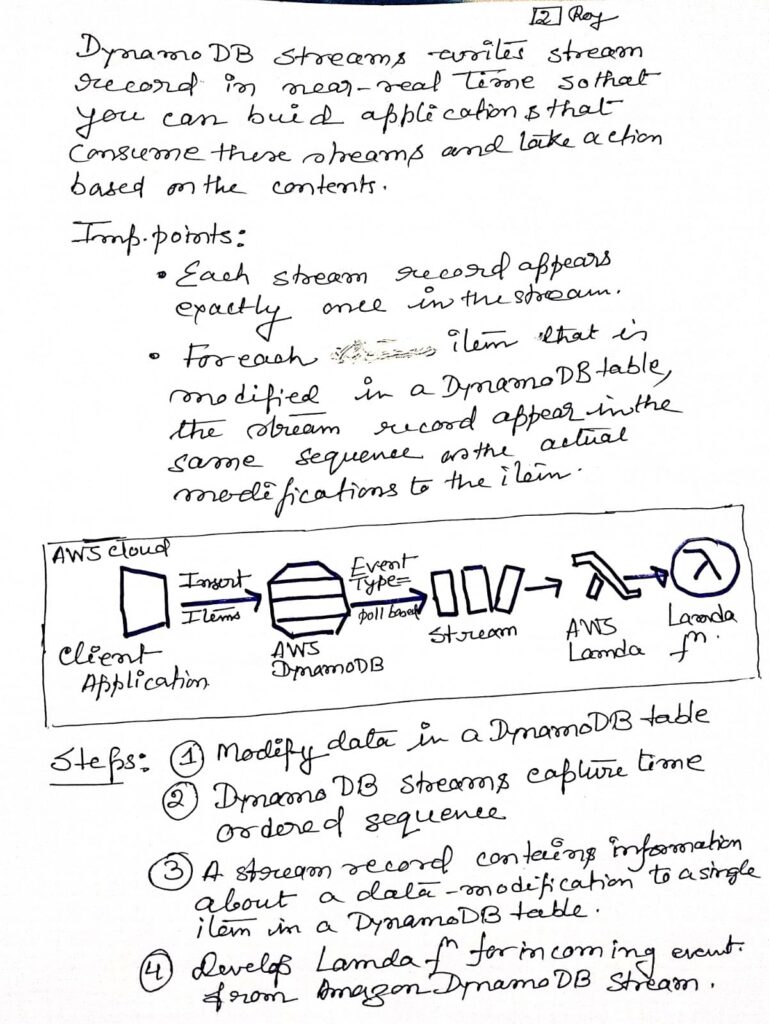
DynamoDB is a high-performance and adaptable NoSQL database service designed for applications that require consistent, low-latency performance, even at large scales. Amazon manages all the underlying infrastructure, ensuring data is redundantly stored across multiple locations within a U.S. Region to support a fault-tolerant architecture. With DynamoDB, you can create tables, insert items, and manage data seamlessly. The system automatically partitions data to meet varying workload demands, with virtually no limit on the number of items a table can hold. Some users, for example, manage production tables with billions of records.
A key advantage of a NoSQL database like DynamoDB is that items within a table can have varying attributes. This allows you to adjust the data structure as your application evolves, enabling you to store both old and new item formats in the same table without requiring complex schema migrations. As your application’s popularity grows, DynamoDB scales effortlessly to accommodate the increased demand for storage. Data is stored on SSDs, ensuring fast, reliable query performance. In addition to scalable storage, DynamoDB allows you to configure the necessary read and write throughput for your tables. This scaling can be managed manually or through automatic scaling, where DynamoDB dynamically adjusts throughput based on workload demands.
Other notable features include global tables that replicate data across selected AWS Regions, encryption to protect data at rest, and the ability to set Time-to-Live (TTL) for individual items.
Here’s a table summarizing the key features of AWS DynamoDB, a fully managed NoSQL database service by Amazon Web Services:
| Feature | Description |
|---|---|
| Data Model | DynamoDB uses a key-value and document data model, allowing for flexibility in storing structured, semi-structured, or unstructured data. |
| Fully Managed | DynamoDB is a fully managed service, meaning AWS handles infrastructure provisioning, maintenance, and scaling. |
| Scalability | It automatically scales throughput capacity based on traffic, supporting horizontal scaling for large workloads. |
| Performance | Offers low latency with single-digit millisecond response times at any scale. It supports high availability through global distribution. |
| Indexing | Provides secondary indexes to allow querying of data beyond the primary key (supports both global and local secondary indexes). |
| Security | Integrated with AWS Identity and Access Management (IAM) for authentication and authorization, and supports encryption at rest using AWS Key Management Service (KMS). |
| Consistency Models | Supports both eventual consistency (faster reads) and strong consistency (guaranteed latest data). |
| Backup and Restore | Offers automated backups (on-demand and continuous), including point-in-time recovery. |
| Durability and Availability | Data is automatically replicated across multiple Availability Zones within an AWS Region, ensuring high availability and durability. |
| Transactions | Supports ACID transactions, enabling atomic, consistent, isolated, and durable operations across multiple items and tables. |
| DAX (DynamoDB Accelerator) | Optional in-memory caching service that reduces read latency for DynamoDB queries from milliseconds to microseconds. |
| Data Streams | DynamoDB Streams enable real-time data changes to be captured and processed, allowing for use cases like triggers or integrations with AWS Lambda. |
| Integration with AWS Ecosystem | Natively integrates with other AWS services, such as AWS Lambda, Amazon Kinesis, Amazon S3, and Amazon Redshift. |
| Pricing Model | DynamoDB uses a pay-per-request pricing model, where you pay for the number of read/write operations or provisioned throughput (with an option for on-demand capacity mode). |
| Use Cases | Ideal for applications requiring high throughput, low-latency data access such as gaming, IoT, mobile apps, e-commerce, and real-time analytics. |
AWS DynamoDB provides the scalability, flexibility, and performance needed for modern, distributed applications.



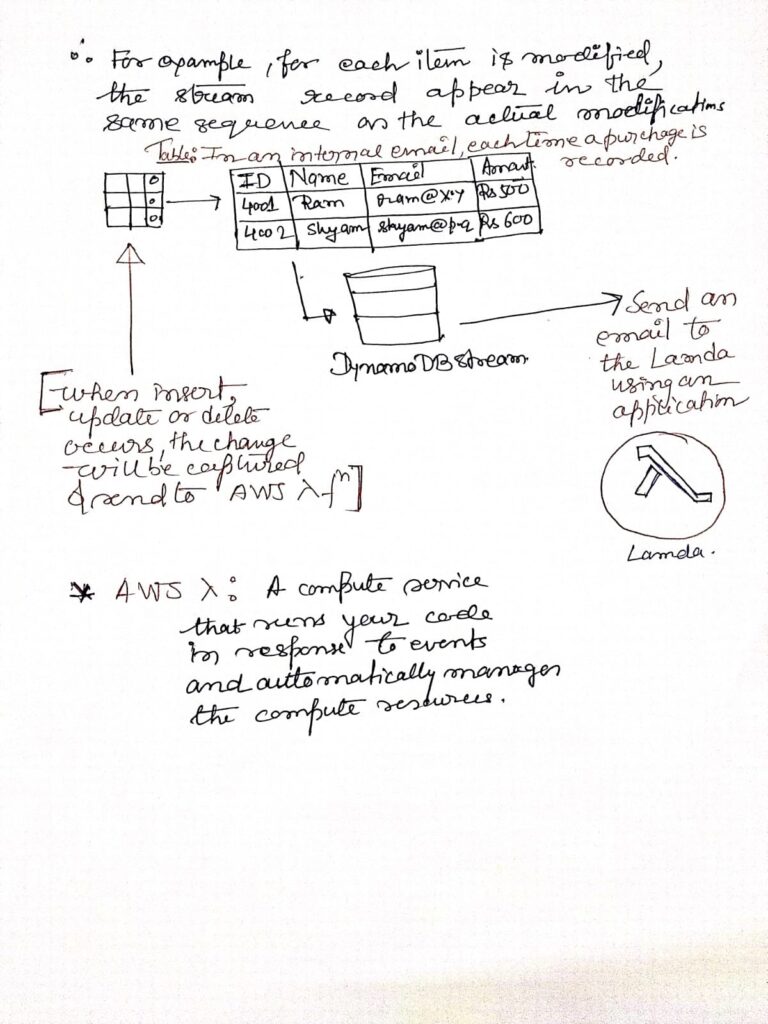
Amazon Redshift
A Fast and Scalable Cloud Data Warehouse
In today’s data-driven world, businesses require efficient, scalable, and cost-effective data solutions. Amazon Redshift is one such solution, offering a powerful, fully managed, petabyte-scale data warehouse service in the cloud. It is designed specifically for Online Analytical Processing (OLAP), making it ideal for high-performance analysis and reporting of large datasets.
What Makes Amazon Redshift Stand Out?
Traditional data warehouses can be difficult and costly to manage, especially when dealing with large datasets. However, Amazon Redshift not only significantly reduces the cost of managing a data warehouse, but it also offers rapid performance, allowing businesses to quickly analyze massive amounts of data. Whether it’s for reporting, data mining, or complex analytics, Redshift is designed to handle big data with ease.
Key Features of Amazon Redshift:
- Fast Query Performance:
Amazon Redshift delivers fast querying capabilities, allowing users to run complex queries over structured data using standard SQL commands. This enables interactive querying over large datasets, which is critical for real-time decision-making and analytics. - High Compatibility:
Built on PostgreSQL, Redshift integrates seamlessly with most existing SQL client applications. It also supports connectivity through ODBC or JDBC, allowing it to work well with various third-party data loading, reporting, data mining, and analytics tools. - Cost-Effectiveness:
One of the primary benefits of Redshift is its ability to lower the cost of data warehousing. It provides a flexible pricing model, enabling businesses to pay only for what they use, which is particularly advantageous for growing organizations that need to scale their data infrastructure. - Managed Infrastructure:
Redshift is a fully managed service, meaning that AWS takes care of all the heavy lifting involved in setting up, operating, and scaling a data warehouse. This includes provisioning the necessary infrastructure, managing backups, and handling software updates and patching, freeing up organizations to focus on analyzing their data rather than maintaining their data warehouse. - Fault Tolerance:
Redshift is designed with built-in fault tolerance. It automatically monitors the health of your nodes and drives, helping to recover from failures and ensuring the smooth operation of your data warehouse.
Architecture of Amazon Redshift: Clusters and Nodes
At the core of Amazon Redshift’s architecture is the cluster. A cluster consists of one leader node and one or more compute nodes. Here’s how these components work together:
- Leader Node: The leader node handles query parsing, planning, and aggregation. It is the point of interaction between the client application and the data warehouse.
- Compute Nodes: These nodes are responsible for executing the queries and processing data. Although they are managed by the leader node, they remain transparent to the external application.
Redshift offers six different node types, categorized into two groups:
- Dense Compute Nodes: These support clusters up to 326TB and are optimized for high-performance querying using fast SSDs.
- Dense Storage Nodes: These support clusters up to 2PB and use large magnetic disks, providing more economical storage options for extremely large datasets.
This flexibility allows businesses to choose the right type of node based on their workload requirements, ensuring that they can efficiently scale their data warehouse as their data needs grow.
Scaling and Performance with Amazon Redshift
Amazon Redshift is designed to handle petabyte-scale data warehouses while maintaining high performance. Whether you’re running complex joins, aggregations, or using Redshift for interactive data analysis, it automatically optimizes your queries to reduce runtime and maximize throughput.
Another significant feature is Elastic Resize, which allows you to scale your clusters in minutes. You can easily add or remove compute nodes to accommodate changing workloads, ensuring that you only pay for the resources you need.
Integrations and Ecosystem
Amazon Redshift integrates with a wide range of AWS services and third-party tools, making it a versatile solution for diverse business needs. Some key integrations include:
- Amazon S3: You can easily load data from S3 into Redshift for analytics, with the ability to process structured and semi-structured data using Amazon Redshift Spectrum.
- Amazon Kinesis: Real-time data streaming and processing from Kinesis allows Redshift to support near real-time analytics on streaming data.
- Amazon Redshift Data Sharing: This feature allows organizations to share live data across different Redshift clusters without needing to make copies, enabling efficient collaboration across departments or business units.
Real-Time Analytics with Redshift
With the emergence of real-time analytics, businesses need solutions that can provide insights as data is being generated. Amazon Redshift supports this with its zero-ETL integration with Amazon Redshift for real-time analytics on transactional data. This integration eliminates the need for complex extract, transform, and load (ETL) pipelines, enabling fast data analysis with minimal overhead.
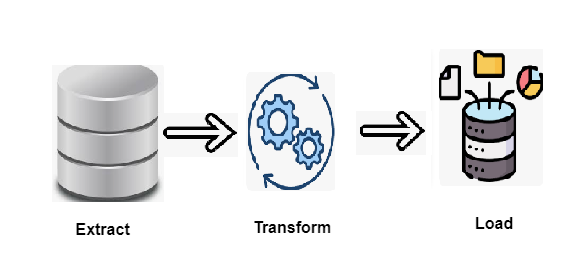
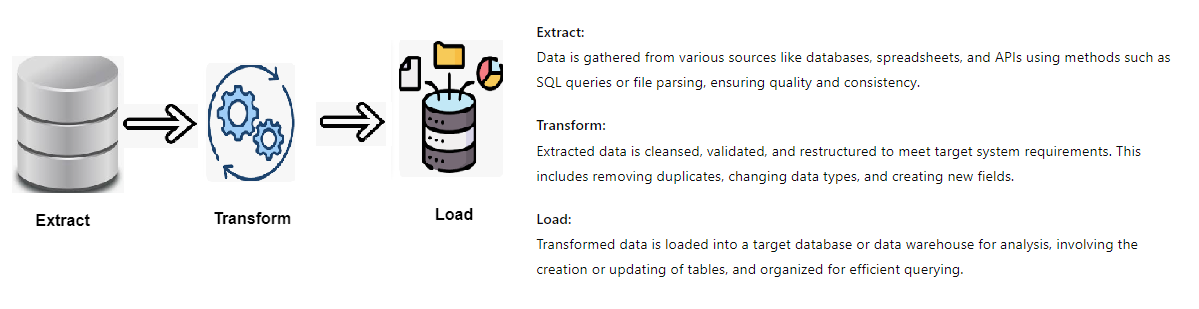
Extraction: The extraction process marks the initial step in the “extract, transform, load” (ETL) workflow. Data is gathered from one or more sources and temporarily stored, allowing for the subsequent phases to take place. During this stage, validation rules are applied to ensure the data complies with the destination’s requirements. Any data that fails these checks is discarded and does not proceed further.
Transformation: In the transformation phase, data undergoes various processes to align both its structure and values with its intended use. The objective here is to ensure that all data conforms to a consistent format before advancing to the next stage. Common transformation processes include aggregation, data masking, expression evaluation, joining, filtering, lookup, ranking, routing, union, XML processing, and converting hierarchical to relational data (H2R) and vice versa (R2H). These operations help standardize and filter the data, preparing it for downstream applications like analytics and business processes.
Loading in the final phase, the processed data is transferred to its permanent destination, which could be a database, data warehouse, data store, data hub, or data lake, either on-premises or in the cloud. Once the data is loaded into the target system, the ETL process is complete. Organizations often repeat this cycle to ensure their data warehouses remain up to date.
Amazon Redshift revolutionizes the traditional concept of a data warehouse by offering a cost-effective, scalable, and high-performance solution for modern businesses. Its fully managed infrastructure, robust fault tolerance, and seamless integrations make it ideal for companies looking to harness the power of big data and real-time analytics. Whether you’re analyzing petabytes of data or scaling your data warehouse to meet growing demands, Redshift is designed to meet the challenges of today’s data-driven world.
Amazon Redshift Cluster Architecture Overview
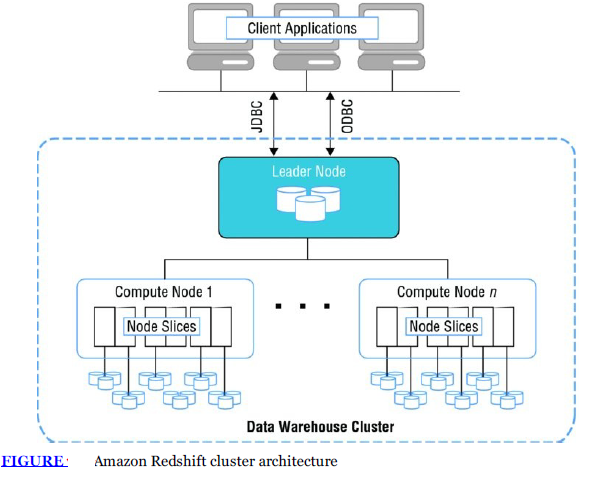
[Image reference: Baron, J., Baz, H., Bixler, T., Gaut, B., Kelly, K. E., Senior, S., & Stamper, J. (2016). AWS certified solutions architect official study guide: associate exam. John Wiley & Sons.Baron, J., Baz, H., Bixler, T., Gaut, B., Kelly, K. E., Senior, S., & Stamper, J. (2016). AWS certified solutions architect official study guide: associate exam. John Wiley & Sons.]
An Amazon Redshift cluster consists of one or more databases, with data distributed across the compute nodes. Client applications or SQL clients communicate with the leader node through JDBC or ODBC connections, and the leader node handles query execution with the compute nodes. The compute nodes, which perform the heavy lifting of query processing, remain invisible to external applications.
Each compute node’s storage is divided into multiple slices, where the number of slices depends on the node size, typically ranging between 2 and 16. Queries are processed in parallel across all slices and nodes, enhancing performance through parallel processing. To further boost query performance, adding more nodes to the cluster allows Amazon Redshift to distribute queries across these nodes. This partitioning strategy enables Amazon Redshift to optimize performance by processing data simultaneously across multiple resources.
Scaling and Resizing Clusters
Amazon Redshift allows for cluster resizing to accommodate growing data storage and compute needs. You can either increase the size of the cluster by adding more nodes or switch to different node types without altering the overall size. When resizing occurs, Redshift migrates data to a new cluster. During this transition, the database becomes read-only until the operation is complete, ensuring data consistency while maintaining flexibility.
Table Design and Data Distribution
Each Amazon Redshift cluster supports multiple databases, with each database capable of hosting numerous tables. Tables are created using standard SQL commands like CREATE TABLE, specifying columns, data types, compression encodings, distribution strategies, and sort keys. One of the critical decisions during table creation is how to distribute the data across the cluster’s compute nodes and slices.
Amazon Redshift offers three primary distribution styles:
- EVEN Distribution – Default option where data is spread evenly across all slices in the cluster, regardless of content.
- KEY Distribution – Data is distributed based on the values in a specific column, improving query performance for joins by keeping related data close.
- ALL Distribution – A full copy of the table is stored on every node, ideal for smaller lookup tables that are infrequently updated.
Selecting the appropriate distribution strategy is crucial for optimizing query performance, reducing storage requirements, and improving system efficiency.
Sort Keys for Query Optimization
Amazon Redshift allows for the specification of sort keys, which dictate the order in which data is stored. Sorting data can improve performance for range-restricted queries by enabling faster scans of relevant data blocks. Redshift supports two types of sort keys:
- Compound Sort Key – Optimizes queries using a prefix of the sort key columns in order.
- Interleaved Sort Key – Gives equal importance to all columns in the sort key, making it flexible for queries that use any subset of the columns.
Loading and Querying Data
Amazon Redshift supports standard SQL commands like INSERT and UPDATE for modifying records. However, for bulk data operations, the COPY command is much more efficient. The COPY command enables fast data loading from flat files stored in Amazon S3 or from DynamoDB tables. When loading data from S3, Redshift can parallelize the process by reading from multiple files simultaneously, significantly reducing load times.
For maintaining data organization after bulk loads, running a VACUUM command helps reclaim space after deletes, and the ANALYZE command updates table statistics to optimize query performance.
To query the data, Redshift supports standard SQL queries, including SELECT commands to extract data. For complex queries, query plans can be analyzed to improve performance. The system also integrates with Amazon CloudWatch for performance monitoring and provides features like Workload Management (WLM) to manage query queues and prioritize workloads for better resource allocation.
Snapshots for Data Protection
Amazon Redshift offers snapshot capabilities similar to Amazon RDS, allowing users to create point-in-time snapshots of their clusters. Snapshots can be used to restore or clone clusters and are stored in Amazon S3. Redshift supports both automated snapshots, which occur at regular intervals, and manual snapshots that can be shared across AWS accounts or regions. Manual snapshots persist until they are explicitly deleted.
Security in Amazon Redshift
Securing your Redshift cluster involves multiple layers of protection:
- Infrastructure Security – AWS IAM policies control the actions that administrators and users can perform, such as scaling, backup, and recovery.
- Network Security – Redshift clusters can be deployed in Amazon VPC with private IP address space, ensuring restricted network access. Security groups and network ACLs provide additional network controls.
- Database Access – A master user account is created during cluster setup, allowing for the creation of users and groups with specific permissions to access database schemas and tables. These database permissions are separate from IAM policies.
- Data Encryption – Redshift offers data encryption both in transit (via SSL connections) and at rest (via AWS KMS-Key Management System or AWS CloudHSM-hardware security module (HSM)) to manage the top-level encryption keys in this hierarchy). Encryption helps meet compliance requirements such as HIPAA and PCI DSS. This overview highlights the powerful capabilities of Amazon Redshift in scaling, performance optimization, table design, data management, and security, making it a leading solution for cloud data warehousing. By addressing security at every level—from infrastructure to data encryption—Amazon Redshift ensures robust protection for your cloud-based data warehouse.
- Few important Information:
- Amazon Redshift uses the Advanced Encryption Standard (AES)-256 encryption algorithm to protect data at rest and in transit:
- Data at rest(data that is saved in non-volatile storage for any amount of time): Amazon Redshift uses hardware-accelerated AES-256 to encrypt all data stored on disks within a cluster and all backups in Amazon S3.
- Data in transit(data that is being moved from one location to another, such as over a network or the internet.): Amazon Redshift uses SSL to secure data in transit.
- Amazon Redshift uses a four-tier, key-based architecture for encryption:
- Data encryption keys: Encrypt data blocks in the cluster using randomly-generated AES-256 keys
- Database key: Encrypts data encryption keys in the cluster using a randomly-generated AES-256 key
- Cluster key: Encrypts the database key for the Amazon Redshift cluster
- Root key: You can use an AWS KMS key as the root key
- Few important Information:
Amazon Aurora
The following diagram depicts how Aurora Fault Tolerance and Replicas work:
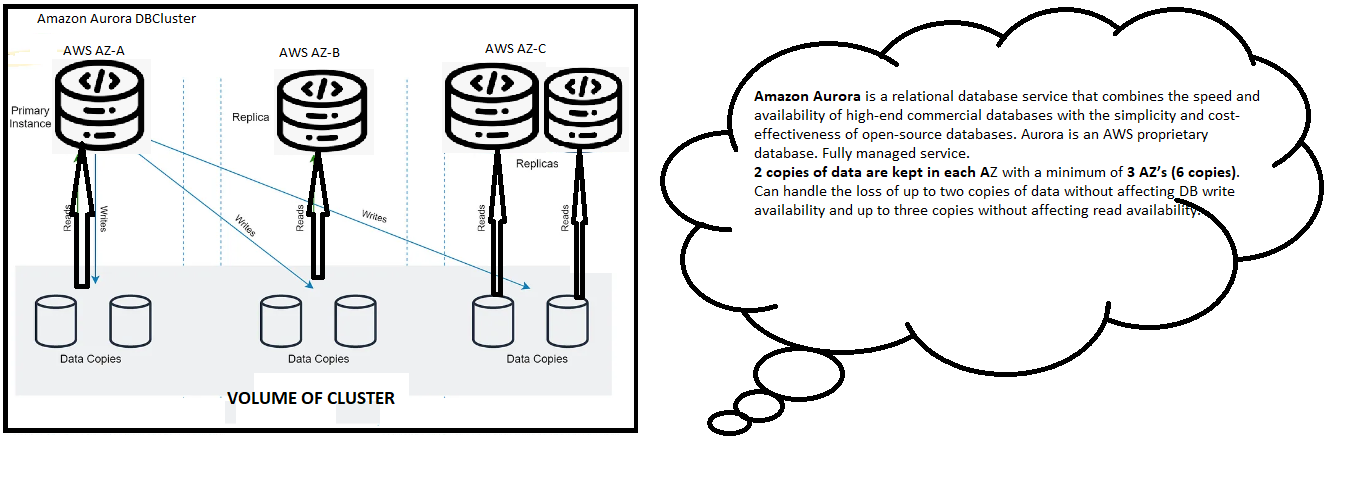
Why Amazon Aurora?
Amazon Aurora stands out for its high performance, scalability, and cost-efficiency. It offers MySQL and PostgreSQL compatibility with significantly enhanced throughput—5x that of MySQL and 3x that of PostgreSQL—while being available at just a tenth of the cost of traditional commercial databases.
Key features of Aurora include:
- Unmatched Performance: Aurora delivers high throughput and low latency, supporting high volumes of transactions effortlessly.
- Global Scalability: Aurora ensures high availability with 99.99% uptime [Uptime measures how long a machine, like a computer or server, is working and available. It is usually shown as a percentage. For example, 99.9% uptime means the server was operational 99.9% of the time. This is very important for businesses that need reliable and fast networks, such as financial services]and supports local read performance across AWS Regions via the Global Database feature.
- Data Durability: It maintains data durability by replicating data across three Availability Zones (AZs), though customers are only charged for one copy.
- Serverless Scaling: With Aurora Serverless, scaling up to handle hundreds of thousands of transactions takes just a fraction of a second, making it ideal for dynamic workloads.
- Zero-ETL Integration: Aurora integrates seamlessly with Amazon Redshift, enabling near real-time analytics on transactional data without needing ETL processes.
- Security and Compliance: Aurora meets extensive compliance standards and provides robust security features, making it suitable for critical workloads.
This combination of features makes Amazon Aurora a top choice for organizations seeking enterprise-grade database performance, reliability, and cost-effectiveness.
Aurora Replicas
There are two types of replication in Aurora: Aurora replicas (up to 15) and MySQL Read Replicas (up to 5).
The table below outlines the differences between these two replica types:
| Feature | Aurora Replica | MySQL Replica |
|---|---|---|
| Number of replicas | Up to 15 | Up to 5 |
| Replication type | Asynchronous (milliseconds) | Asynchronous (seconds) |
| Performance impact on primary | Low | High |
| Replica location | In-region | Cross-region |
| Acts as failover target | Yes (no data loss) | Yes (possible minutes of data loss) |
| Automated failover | Yes | No |
| Supports user-defined replication delay | No | Yes |
| Allows different data/schema from primary | No | Yes |
You can create read replicas of an Amazon Aurora database across up to five AWS regions. This feature is available for Aurora with MySQL compatibility.
Cross-Region Read Replicas
Cross-region read replicas enhance disaster recovery, scale read operations closer to your users, and facilitate smooth migration between regions.
These replicas provide faster local reads to users. Each region can support an additional 15 Aurora replicas to increase read scalability.
You can choose between Global Database, which offers optimal replication performance, or the traditional binlog-based replication. You can also set up binlog replication with external MySQL databases.
Global Database
For applications with global distribution, Global Database allows a single Aurora database to span multiple AWS regions, enabling fast local reads and rapid disaster recovery.
Global Database uses storage-based replication, ensuring database replication across regions with a typical latency of less than 1 second. A secondary region can act as a backup, allowing full read/write capability within a minute of failover.
Multi-Master
Amazon Aurora’s Multi-Master feature, available in the MySQL-compatible edition, lets you distribute write operations across multiple Availability Zones, improving scalability and availability.
With Multi-Master, all database nodes in the cluster are read/write nodes, offering high availability and ACID compliance. In the event of a failure, other nodes continue operation, ensuring no single point of failure.
Architecture
An Aurora cluster consists of multiple compute nodes and a shared storage volume. The storage spans six nodes across three Availability Zones for data durability and high availability. All database nodes are equal in functionality, meaning any node can handle both read and write operations. Data changes made by any node are replicated across storage nodes in three Availability Zones.
High Availability
Aurora Multi-Master enhances availability by allowing all nodes in the cluster to handle read/write operations. If one node fails, the application can redirect to another node without significant impact.
Aurora Serverless
Amazon Aurora Serverless is an on-demand, auto-scaling configuration that adjusts based on application needs, available for both MySQL and PostgreSQL-compatible editions. It automatically scales, starts, and stops the database based on activity, making it ideal for intermittent or unpredictable workloads.
You only pay for storage, database capacity, and I/O used while the database is active, billed per second. Migration between standard and serverless configurations can be done easily via the Amazon RDS Management Console.
Use Cases for Aurora Serverless:
| Use Case | Example |
|---|---|
| Infrequently Used Applications | Applications used a few times a day or week. Pay only for resources consumed. |
| New Applications | Deploying a new app with unknown capacity needs. The database auto-scales. |
| Variable Workloads | Light usage with occasional peaks. Pay only for resources needed. |
| Unpredictable Workloads | Workloads with unpredictable peaks, auto-scaling handles the changes. |
| Development & Testing | Automatically shuts down during off-hours, saving costs. |
| Multitenant Applications | Manage database capacity for multiple customers without manual intervention. |
Fault-Tolerant and Self-Healing Storage
Aurora’s storage replicates data across six copies in three Availability Zones. It can handle the loss of two data copies without affecting write availability and up to three copies without affecting reads. The system continuously scans for errors and automatically replaces faulty data blocks.
Aurora Auto Scaling
Aurora Auto Scaling automatically adjusts the number of Aurora replicas in response to changes in traffic or workload. It scales down when demand decreases, saving costs by removing unused replicas.
Backup and Restore
Amazon Aurora offers point-in-time recovery, allowing you to restore a database to any moment within the retention period, up to the last five minutes. Backups are automatic, continuous, and stored in Amazon S3. The retention period can be set up to 35 days.
Backup options:
- Automated backups: Daily snapshots and transaction logs stored in multiple Availability Zones.
- Manual backups: User-initiated snapshots.
Restoring from backups creates a new database instance with a fresh endpoint, and the storage type can be changed during restoration.By default, backups are retained for seven days, but this can be extended to 35 days. For Aurora, the retention period is one day regardless of configuration method.
Use cases
Modernize enterprise applications
Operate enterprise applications, such as customer relationship management (CRM), enterprise resource planning (ERP), supply chain, and billing applications, with high availability and performance.
Build SaaS applications
Support reliable, high- performance, and multi-tenant Software-as a-Service (SaaS) applications with flexible instance and storage scaling.
Deploy globally distributed applications
Develop internet-scale applications, such as mobile games, social media apps, and online services, that require multi-Region scalability and resilience.
Go serverless
Hands-off capacity management, and pay only for capacity consumed with instantaneous and fine-grained scaling to save up to 90% of cost.
Samsung moved one billion user accounts to Aurora
Amazon Aurora is a modern relational database service. It offers unparalleled high performance and high availability at global scale with fully open-source MySQL– and PostgreSQL-compatible editions and a range of developer tools for building serverless and machine learning (ML)-driven applications. Choose the Aurora pricing that is right for your business needs, with predictable, pay-as-you-go, On-Demand, or Reserved Instance pricing. Aurora charges for database instances, storage, and I/O based on database cluster configuration, along with any optional features you choose to enable.
Aurora cluster configuration
With Aurora, you can configure your database clusters to run cost effectively, regardless of the scaling needs or evolving data access patterns of your applications. You have the flexibility to choose between the Amazon Aurora Standard and Amazon Aurora I/O-Optimized configuration options to best match the price-performance and price-predictability requirements of your unique workload characteristics. Your database instance, storage, and I/O charges will vary based on the option you choose. To learn more, visit Amazon Aurora storage and reliability.
Aurora Standard offers cost-effective pricing for the vast majority of applications running on Aurora with typical data access patterns and low to moderate I/O usage. With Aurora Standard, you pay for your database instances, storage, and pay-per-request I/O.
Aurora I/O-Optimized delivers improved price performance for I/O-intensive applications. If your I/O spend exceeds 25% of your total Aurora database spend, you can save up to 40% on costs for I/O-intensive workloads with Aurora I/O-Optimized. With Aurora I/O-Optimized, you only pay for your database instances and storage usage, and there are zero charges for read and write I/O operations. Aurora I/O-Optimized offers predictable pricing for all applications regardless of evolving data access patterns or I/O usage. Aurora I/O-Optimized eliminates variability in I/O spend.
Pricing by database instances
With Aurora, you can choose Amazon Aurora Serverless, which automatically starts up, shuts down, and scales capacity up or down based on your application’s needs; you pay only for capacity consumed. Alternatively, you can choose Provisioned On-Demand Instances and pay for your database per DB instance-hour consumed with no long-term commitments or upfront fees, or choose Provisioned Reserved Instances for additional savings. Instance charges apply to both Aurora primary instances and Replicas. The charges will vary based on the database cluster configuration you choose to best match the price-performance and price-predictability needs of your application. All instances in a database cluster will either be charged the price for the Aurora Standard or Aurora I/O-Optimized configuration.
Optimized Reads instances for Aurora PostgreSQL
Optimized Reads instances available for Amazon Aurora PostgreSQL-Compatible Edition use local NVMe-based SSD block-level storage to improve query latency of applications with data sets exceeding the memory capacity of a database instance. It includes two features: tiered caching and temporary objects.
Tiered caching delivers up to 8x improved query latency and up to 30% cost savings for read-heavy, I/O-intensive applications such as operational dashboards, anomaly detection, and vector-based similarity searches. Tiered caching automatically stores data evicted from the in-memory database buffer cache onto local storage to speed up subsequent data accesses. Tiered caching is available for Aurora PostgreSQL with the Aurora I/O-Optimized configuration.
Temporary objects achieve faster query processing by placing temporary tables on local storage, improving the performance of queries involving sorts, hash aggregations, high-load joins, and other data-intensive operations. Temporary objects is available for Aurora PostgreSQL with the Aurora I/O-Optimized and Aurora Standard configurations. To learn more, visit Amazon Aurora Optimized Reads.
Select “Aurora MySQL-Compatible Edition” or “Aurora PostgreSQL-Compatible Edition” to view database instance pricing.
Pricing by database storage and I/Os
With Aurora, you do not need to provision either storage or I/O operations in advance, and both scale automatically. The fault-tolerant distributed storage of Aurora automatically makes your data durable across three Availability Zones in a Region. You only pay for one copy of the data.
Aurora storage is billed in per GB-month increments at the rates shown in the following table for the Aurora Standard and Aurora I/O-Optimized configurations. With Aurora Standard, you pay for the storage and I/O operations that your Aurora database consumes. I/O charges may vary significantly depending on workload and database engine. To learn more about I/O operations, visit the Aurora FAQ, “Q: What are I/O operations in Aurora and how are they calculated?” With Aurora I/O-Optimized, you are not charged for read and write I/O operations.
Region:US East (Ohio)
| Component | Aurora Standard | Aurora I/O-Optimized |
|---|---|---|
| Storage Rate | $0.10 per GB-month | $0.225 per GB-month |
| I/O Rate | $0.20 per 1 million requests | Included |
Create your custom estimate for Aurora PostgreSQL now »
Aurora Global Database costs
Amazon Aurora Global Database is designed for globally distributed applications, allowing a single Aurora database to span multiple Regions. It replicates your data with no impact on database performance, enables fast local reads with low latency in each Region, and provides disaster recovery from Region-wide outages.
With Aurora Global Database, you pay for replicated write I/O operations between the primary Region and each secondary Region. The number of replicated write I/O operations to each secondary Region is the same as the number of in-Region write I/O operations performed by the primary Region. You pay for replicated write I/O operations with both Aurora Standard and Aurora I/O-Optimized configuration options. Apart from replicated write I/Os, you pay for instances, storage, and I/O usage in the primary and secondary Regions based on the cluster configuration you choose, along with cross-Region data transfer, backup storage, and other billable Aurora features.
Region:US East (Ohio)
| Measure | Pricing |
|---|---|
| Replicated Write I/Os | $0.20 per million replicated write I/Os |
Backup storage costs
Backup storage for Aurora is the storage associated with your automated database backups and any customer-initiated database cluster snapshots.
You are not charged for the backup storage of up to 100% of the size of your database cluster. There is also no charge for database snapshots created within the backup retention period. For all other backups and snapshots (including those from deleted clusters), usage is metered per GB-month at the following rates:
Region:US East (Ohio)
| Measure | Pricing |
|---|---|
| Backup Storage | $0.021 per GB-month |
Backtrack costs
Backtrack lets you quickly move an Aurora database to a prior point in time without needing to restore data from a backup. This lets you quickly recover from user errors, such as dropping the wrong table or deleting the wrong row. This feature is currently available for the MySQL-compatible edition of Aurora. Specify how far in the past you want to be able to backtrack (for example, up to 24 hours). Aurora will retain logs, called change records, for the specified backtrack duration. You pay an hourly rate for storing change records.
Read the detailed backtrack pricing example.
Region:US East (Ohio)
| Measure | Price Per Hour |
|---|---|
| Change Records | $0.012 per 1 million Change Records |
Data API costs
Data API is an easy-to-use, secure HTTPS API for executing SQL queries against Aurora databases that accelerates modern application development. Data API eliminates network and application configuration tasks needed to securely connect to an Aurora database, which makes accessing Aurora as simple as making an API call. With Data API, you only pay when your API is in use. There are no minimum fees or upfront commitments. You pay only for the API and data requests your applications make. Data API request data payloads are metered at 32KB per request for data sent to the API or received from the API. If your API request data payload size is larger than 32KB, then for each 32KB increment there is a charge of one additional API request. So, if your payload is 35KB for example, you would be charged for two API requests. Data API free tier includes one million API requests per month, aggregated across AWS Regions, for the first year.
Customers will also incur charges for AWS Secrets Manager and may also incur additional charges for AWS CloudTrail, if activated.
Region:US East (Ohio)
API Requests
| Number of Requests (per month) | Price (per million) |
|---|---|
| First 1 Billion requests | $0.35 |
| Above 1 Billion requests | $0.20 |
Aurora PostgreSQL and Aurora MySQL are each billed separately for the purposes of price tiers.
Data transfer costs
The pricing below is based on data transferred “in” and “out” of Aurora.
- As part of the AWS Free Tier, AWS customers receive 100 GB of free data transferred out to the internet for free each month, aggregated across all AWS services and Regions (except China (Beijing), China (Ningxia), and GovCloud (US)).
- Data transferred between Aurora and Amazon Elastic Compute Cloud (Amazon EC2) instances in the same Availability Zone is free.
- Data transferred between Availability Zones for DB cluster replication is free.
- For data transferred between an Amazon EC2 instance and Aurora DB instance in different Availability Zones of the same Region, Amazon EC2 Regional Data Transfer charges apply.
Region:US East (Ohio)
| Data Transfer IN To Amazon RDS From Internet | Pricing |
|---|---|
| All data transfer in | $0.00 per GB |