Introduction to Ensemble Methods
Ensemble learning refers to a family of techniques where multiple models are combined to build a more powerful and accurate predictor. Well-known ensemble approaches include bagging, boosting, and random forests.
The central idea is to train a collection of models, often called base classifiers (M₁, M₂, …, Mₖ), and then merge their outputs to form a stronger meta-classifier (M*). Instead of relying on a single learning model, the ensemble leverages the collective wisdom of many models.
Given a dataset D, we generate k different training subsets (D₁, D₂, …, Dₖ). Each subset is used to build one base classifier. When a new data point needs to be classified, each model provides its own prediction (a “vote”). The ensemble aggregates these predictions—often through majority voting—and produces the final decision.
Ensembles typically outperform individual models. For example, if the ensemble relies on majority voting, it will only misclassify a data point if more than half of its base classifiers are wrong. Thus, even when some models make mistakes, the combined decision can still be correct.
The strength of an ensemble lies in diversity—the models should not all make the same types of errors. Low correlation among base classifiers ensures that their mistakes are less likely to overlap. Importantly, each model should perform better than random guessing to contribute meaningfully. Another advantage is that ensemble methods can be parallelized, since each classifier can be trained independently on different processors.
To illustrate, consider a two-class problem with attributes x₁ and x₂. A single decision tree might generate a rough, piecewise-constant decision boundary. However, when we combine many such trees into an ensemble, the resulting decision surface becomes more refined and closer to the true boundary—demonstrating the increased accuracy of ensembles.
Bagging: Bootstrap Aggregation
Bagging is one of the simplest yet most effective ensemble techniques. Its goal is to improve prediction accuracy by reducing variance in the models.
Algorithm: Bagging
Input:
- D, a dataset of d training examples
- k, the number of models to be combined
- A base learning algorithm (e.g., decision trees, naïve Bayes, etc.)
Process:
- For i = 1 to k:
a. Generate a bootstrap sample Dᵢ by sampling from D with replacement.
b. Train a classifier Mᵢ on Dᵢ using the chosen learning algorithm. - To classify a new instance X:
- Let each Mᵢ predict the class of X.
- Output the class label with the majority vote.
This method is called bootstrap aggregation because each subset is a bootstrap sample. Since sampling is with replacement, some data points from D may appear multiple times in Dᵢ, while others may be excluded.
Why Bagging Works?
Bagging improves robustness, especially against noisy data and overfitting. By averaging across many classifiers, it reduces variance without substantially increasing bias.
A simple analogy is medical diagnosis: instead of asking just one doctor, you consult many doctors. Each gives a possible diagnosis, and the final decision is made based on the majority opinion. This aggregated decision is usually more reliable than relying on a single opinion.
Regression Case
When applied to regression, bagging predicts continuous values by averaging the outputs of the base models rather than voting.
Advantages
- Improves accuracy compared to a single classifier.
- Rarely performs worse than the base model.
- Works well with high-variance models like decision trees.
In practice, bagging often delivers a substantial performance boost and forms the basis of more advanced ensemble methods such as random forests.
Boosting and AdaBoost
Boosting is another popular ensemble learning technique that improves accuracy by assigning different weights to classifiers and training samples. Imagine consulting multiple doctors for a diagnosis—not only do you gather their opinions, but you also give more importance (weight) to the doctors who have been more accurate in the past. Similarly, in boosting, classifiers with better performance get stronger influence in the final decision.
How Boosting Works
- Each training instance is given a weight.
- A sequence of classifiers is trained iteratively. After each classifier Mᵢ is built, the weights of the training data are adjusted:
- Misclassified samples get higher weights so that the next classifier pays more attention to them.
- Correctly classified samples get lower weights.
- The final ensemble model combines all classifiers, but instead of equal voting (like bagging), each classifier’s vote is weighted by its accuracy.
This way, boosting builds a set of models that complement one another—later classifiers focus more on the harder cases that earlier ones got wrong.
AdaBoost (Adaptive Boosting)
AdaBoost is the most widely used boosting algorithm. It starts by giving equal weight (1/d) to all training tuples. Then it proceeds for k rounds:
- Sampling: In each round, a training set Dᵢ of size d is created by sampling with replacement. The chance of a tuple being selected depends on its weight.
- Training: A classifier Mᵢ is trained on Dᵢ.
- Error Calculation: The error of Mᵢ is measured as the total weight of misclassified samples. If error > 0.5, the classifier is discarded.
- Weight Update:
- Misclassified tuples get higher weights.
- Correctly classified tuples get lower weights.
- Weights are normalized so they always sum to 1.
This ensures that difficult-to-classify tuples receive more attention in the next round.
Weighted Voting in AdaBoost
When classifying a new instance X:
- Each classifier Mᵢ contributes a weighted vote.
- The weight is based on its accuracy and computed as:
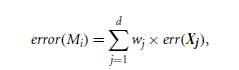

- The class label with the highest total weighted vote across all classifiers is chosen as the final prediction.
Bagging vs. Boosting
- Bagging treats all classifiers equally and reduces variance by averaging votes.
- Boosting gives higher weight to more accurate classifiers and focuses on reducing both bias and variance by concentrating on difficult training samples.
As a result, boosting often delivers higher accuracy than bagging, though it can be more sensitive to noisy data.
Adaboost
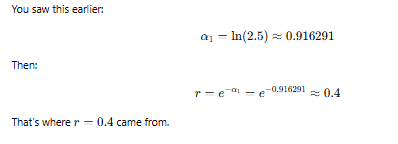
Adaboost Numerical